
Makine Öğrenimi (ML) ve Unutulan Dillerin Deşifresi
- Hüseyin GÜZEL

- Apr 7, 2024
- 4 min read
Updated: Aug 3, 2025
Makine öğrenimi (Machine Learning) unutulan kayıp dilleri otomatik olarak çevirmek için uzun yıllardır kullanılıyor... Makine öğrenimi sayesinde makine çeviri işlemi ile hiç bir zaman çözülmeyen bazı dillerin gizemini keşfedebileceğiz belki de...

1886'da İngiliz arkeolog Arthur Evans, bilinmeyen bir dilde ilginç bir yazıt olan antik bir taşa rastladı. Taş, Akdeniz'in Girit adasından eline ulaşmıştı ve Evans daha fazla kanıt bulabilmek için hemen oraya gitti. Çok kısa sürede M.Ö. 1400'lerden kalma çok sayıda benzer senaryo yazılardan oluşan taş ve tabletler buldu.
Bu yazıt şimdiye dek keşfedilen en eski yazma biçimlerinden biriydi. Evans, doğrusal biçimin açıkça sanatın ilk dönemine ait kabaca çizilen çizgi resimlerinden kaynaklandığını savundu, böylece dilbilim tarihindeki önemini ortaya çıkardı.
O ve diğerleri, taşların ve tabletlerin iki ayrı senaryoda yazıldığını tespit etti. Doğrusal A olarak adlandırılan en eskisi olan ve adadaki Tunç Çağı Minoan medeniyetinin egemen olduğu M.Ö. 1800-1400 yılları arasına tekabül ediyor.

Diğer senaryo Doğrusal B ise daha yenidir, ancak MÖ 1400'den sonra, adanın Yunan anakarasındaki Mikenliler tarafından fethedilmesiyle ortaya çıkmıştır.
Evans ve diğerleri yıllarca eski senaryoları deşifre etmeye çalıştılar, ancak kayıp diller tüm denemelere karşın çözülemedi. Michael Ventris adlı amatör bir dilbilimci Doğrusal B'nin gizemini taki 1953 yılında kırana kadar.
Onun çözümü iki belirleyici buluş üzerine inşa edilmişti. ilki, Ventris Doğrusal B kelime haznesinde tekrarlanan kelimelerin çoğunun Girit adasındaki yerlerin isimleri olduğunu varsaydı. Bu doğru çıktı.
Diğeri ise, yazının eski Yunanca bir form kaydettiğini varsaymaktı. Bu varsayım çok hızlı bir şekilde dilin geri kalanını deşifre etmesini sağladı. Bu süreçte Ventris, eski Yunanlıların ilk defa, daha önceden düşünülenden çok daha yüzyıllar öncesinde yazılı olarak ortaya çıktıklarını ortaya koydu.
Ventris’in çalışmaları büyük bir başarıydı. Ancak daha eski senaryo olan Doğrusal A, dilbilimde bugüne kadar karşılaşılan en büyük problemlerden biri olarak kaldı.
Makine çevirisindeki son gelişmelerin yardımcı olabileceğini hayal etmek de zor değil artık. Sadece birkaç yıl içerisindeki dilbilim çalışmaları, büyük veritabanlarının mevcudiyeti ve makinelerin onlardan öğrenmelerini sağlamak için kullanılan teknikler ile devrim niteliğinde bir gelişme gösterdi. Sonuç olarak, bir dilden diğerine makine çevirisi rutin hale geldi. Mükemmel olmasa da, bu yöntemler dil hakkında düşünmek için tamamen yeni bir yol-yöntem sağladı.
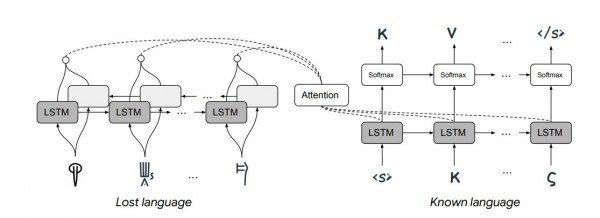
MIT’den Jiaming Luo ve Regina Barzilay’e, Kaliforniya’daki Mountain View’deki Google’ın AI (Yapay Zeka) laboratuarından Yuan Cao. Bu ekip, kayıp dilleri deşifre edebilen bir makine öğrenme sistemi geliştirdi ve bunu ilk kez otomatik olarak yapıldığı zaman Doğrusal B'yi deşifre ederek kanıtladılar. Kullandıkları yaklaşım, standart makine çevirisi tekniklerinden çok farklıydı.
Öncelikle, makine çevirisinin ardındaki büyük fikir; söz konusu dilden bağımsız olarak kelimelerin birbirleriyle benzer şekilde ilişkili olduğunun anlaşılmasıdır.
Böylece süreç, bu ilişkileri belirli bir dil için haritalandırarak başladı. Bu, metin için büyük veritabanları gerektirdi. Bir makine daha sonra, her kelimenin diğer her kelimenin yanında ne sıklıkta göründüğünü görmek için bu metinde aramalar yaptı. Bu görünüş biçimi, kelimeyi çok boyutlu bir parametre uzayında tanımlayan eşsiz bir imzadır. Gerçekten de, kelime, bu şekilde boşluktaki bir vektör olarak düşünülebilir. Ve bu vektör, makinenin geldiği herhangi bir çeviride kelimenin nasıl görünebileceği konusunda güçlü bir kısıtlama ve belirleyici olarak hareket etmesini sağladı.
Bu vektörler bazı basit matematik kurallarına uyar. Örneğin: kral - erkek + kadın = kraliçe. Ve bir cümle, bu boşlukta bir tür yörünge oluşturmak için birbiri ardına gelen bir dizi vektör olarak düşünülebilir.
Makine çevirisini sağlayan ana fikir, farklı dillerdeki kelimelerin ilgili parametre alanlarında aynı noktaları işgal etmesidir. Ve bu, bir dili birebir benzer yazışmalar ile tüm bir dili başka bir dile eşleştirmeyi mümkün kılar.
Bu şekilde, cümlelerin çevrilme süreci, bu alanlarda benzer yörüngelerin bulunması süreci haline geldi. Makine asla cümlenin ne anlama geldiğini “bilmek” zorunda kalmaz.
Bu işlem büyük veri kümelerine büyük ölçüde güvenir. Ancak birkaç yıl önce, bir Alman araştırma ekibi, çok daha küçük veritabanlarıyla benzer bir yaklaşımın, metnin büyük veritabanlarından yoksun olan daha nadir dillerin çevrilmesine nasıl yardımcı olabileceğini de ortaya koymayı başardı. İşin püf noktası, veritabanına dayanmayan makine yaklaşımını sınırlamanın farklı bir yolunu bulmaktır.
Artık dilbilimci olan Luo ve Co, makine çevirisinin tamamen kaybedilen dilleri nasıl çözebileceğini göstermek için daha da ileriye gittiler. Kullandıkları kısıtlama, dillerin zaman içinde geliştiği bilinen yöntemle de ilgilidir.
Buradaki düşünce, herhangi bir dilin yalnızca belirli şekillerde değişebileceğidir; örneğin, ilgili dillerdeki semboller benzer dağılımlarla görünür, ilgili kelimeler aynı karakter sırasına sahiptir, vb. Makineyi kısıtlayan bu kurallarla, ata dil öğrenilir ise, bir dilin şifresini çözmek çok daha kolay hale gelir.
Luo ve Co, tekniği iki kayıp dil olan Doğrusal B ve Ugaritic ile teste tabi tuttu. Bu dilbilimciler, Doğrusal B'nin eski Yunanca'nın eski bir versiyonunu kodladığını ve 1929'da keşfedilen Ugaritik'in ise eski bir İbranice biçimi olduğunu ortaya koydular.

Dilbilimsel evrimin getirdiği bilgi ve kısıtlamalar göz önüne alındığında, Luo ve Co’nun makinesi her iki dili de dikkate değer bir doğrulukla çevirebiliyor. “Deşifre senaryosundaki Doğrusal B bilişlerinin % 67,3'ünü Yunanca eşdeğerlerine doğru şekilde çevirebildik” dediler. “Bildiğimiz kadarıyla, deneyimiz Doğrusal B'yi otomatik olarak deşifre etmenin ilk girişimidir.”
Bu, makine çevirisini yeni bir seviyeye getiren etkileyici bir çalışmadır. Ancak aynı zamanda, diğer Doğrusal A gibi, özellikle de hiç çözülmeyen diller gibi, ilginç dillerin ilginç sorusunu da gündeme getirmektedir.
Bu yazıda, Doğrusal A, olmaması ile dikkat çekiyor. Luo ve Co bundan bahsetmiyorlar bile, ancak bütün dilbilimciler için olduğu gibi, akıllarında büyük bir yer tutuyor olduğundan eminiz. Yine de, bu komut dosyası makine çevirisine uygun hale gelmeden önce hala önemli gelişmelere ihtiyaç var.
Örneğin, hiç kimse Doğrusal A'nın hangi dili kodladığını bilmiyor. Eski Yunancaya deşifre etme girişimlerinin hepsi başarısız oldu. Ve progenitör (ata) dili olmadan, bu yeni teknik işe yaramıyor.
Ancak, makine temelli yaklaşımların en büyük avantajı, bir dili birbiri ardına yorulmadan hızlıca test edebilmeleridir. Bu nedenle, Luo ve Co'nun Doğrusal A'yı kaba kuvvet yaklaşımıyla ele alması oldukça muhtemeldir.
Eğer bu işe yararsa, Michael Ventris'in bile hayran kalacağı etkileyici bir başarı ortaya çıkacak.
Referans: arxiv.org/abs/1906.06718 : Minimum Maliyet Akışı ile Sinirsel Deşifre: Ugaritik'ten Lineer B'ye - MIT Technology Review





Comments